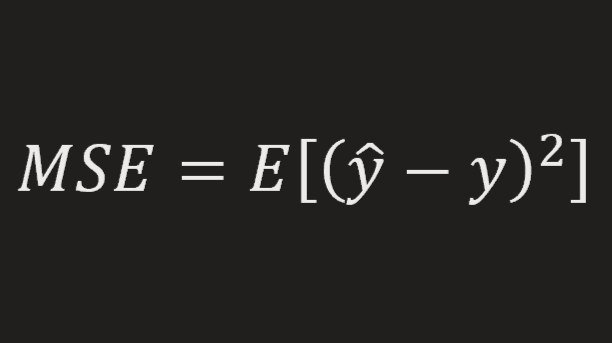K-Means Clustering Simulation
-
-

-
K-means clustering might be the most popular and simplest one among the clustering methods The procedure is as follows:
- Specify the number of clusters.
- Add an initial center point for each cluster.
- For each data points, calculate its distance from cluster centers and choose the nearest one as the cluster of that point.
- Update the cluster center positions according to the points in clusters.
- Repeat 3-4 until the algorithm converges to a certain solution.
I prepared the widget below long time ago. It shows the iterations of that k-means clustering process for a randomly generated data with two variables.
- "New Data" button generates data points to use.
- "Generate Groups" button creates random cluster centers.
- "Iterate Groups" button does the step 3 and step 4 in the algorithm. You can see the further iterations by clicking this button.
Document
Recent Posts